Data-Driven Approaches to Building Equitable Language-Based Mental Health Assessments
Steven
2025-10-11
Outline
- Background
- Research Aims
- Design/Measures
- Questions for you
Background
- The U.S. is experiencing a mental health crisis (anxiety & depression).
- Access to care is unequal, especially for racial and ethnic minority groups.
- Language-based assessments promise scalable screening but recent evidence shows reduced performance for minority groups — risking widened disparities (see Rai et al., 2024).
Rai et al. (2024) Figures
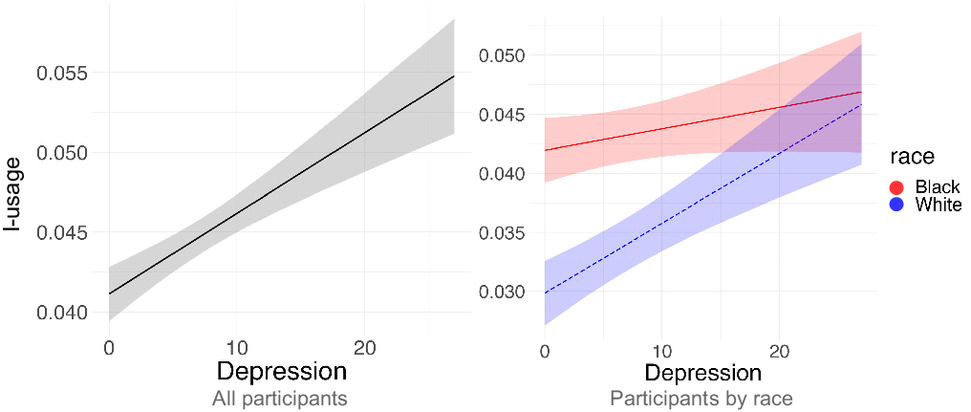
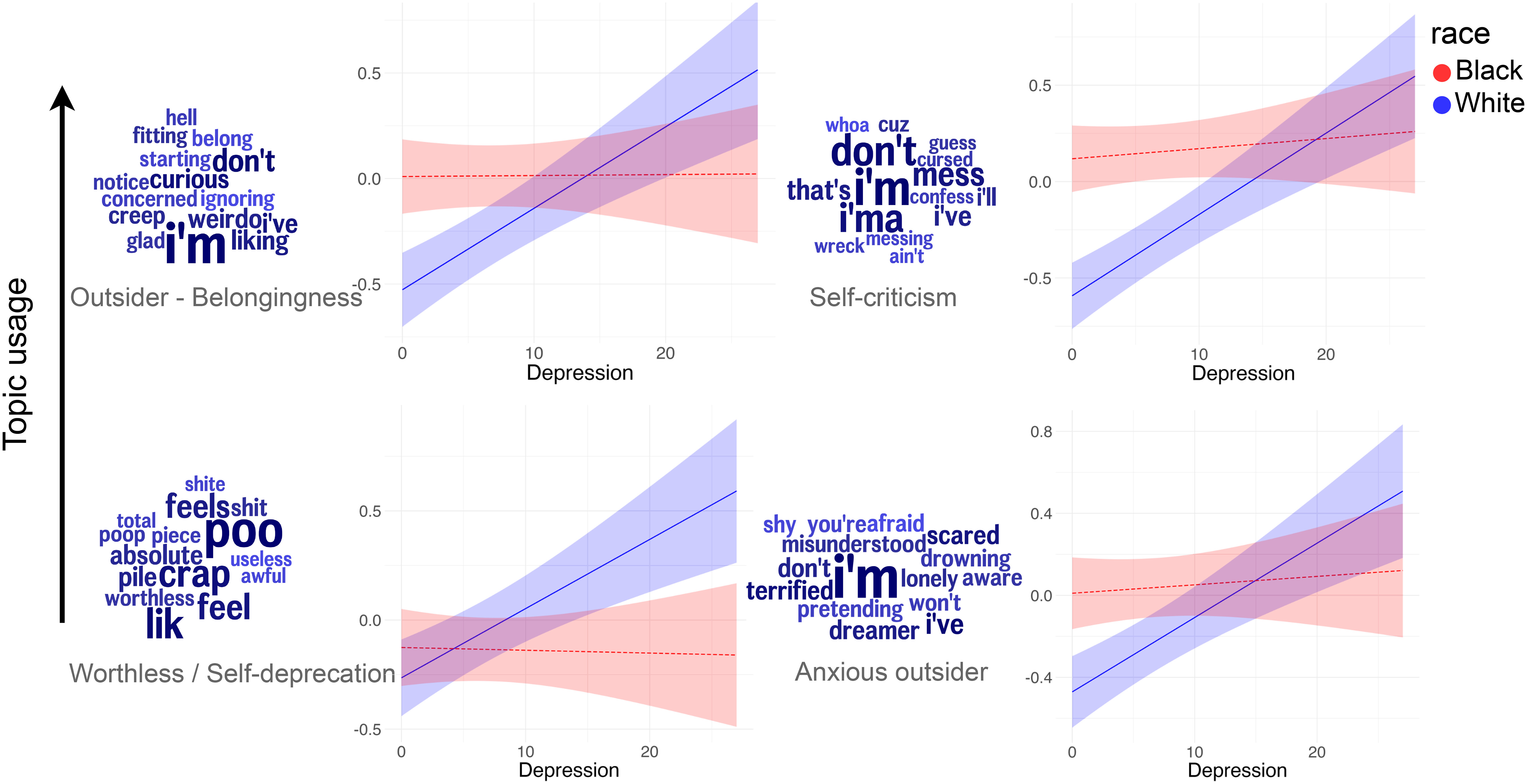
Research Aims
- Aim 1: Test the sensitivity of language-based mental health assessments across a diverse set of racial and ethnic groups (i.e., White, Black, Latino, and Asian) in predicting current and future anxiety and depression symptoms.
- Aim 2: Explore the linguistic markers of anxiety and depression in racial and ethnic minorities.
Design
Description - Two-session online longitudinal study. - Baseline: open-text responses about mood, motivation, sleep (≈25 min) + GAD-7 + PHQ-8. - Follow-up (3 weeks later): repeat assessments (≈10 min) and collect information on posts from social media.
- N = 1,600 (ages 18–40), balanced by race/ethnicity (White, Black, Latino, Asian).
- Recruitment platform: Online panel (e.g., Prolific/CloudResearch) with demographic quotas.
- Pilot: N = 240 to validate prompts, retention, and preprocessing pipelines.
Flow
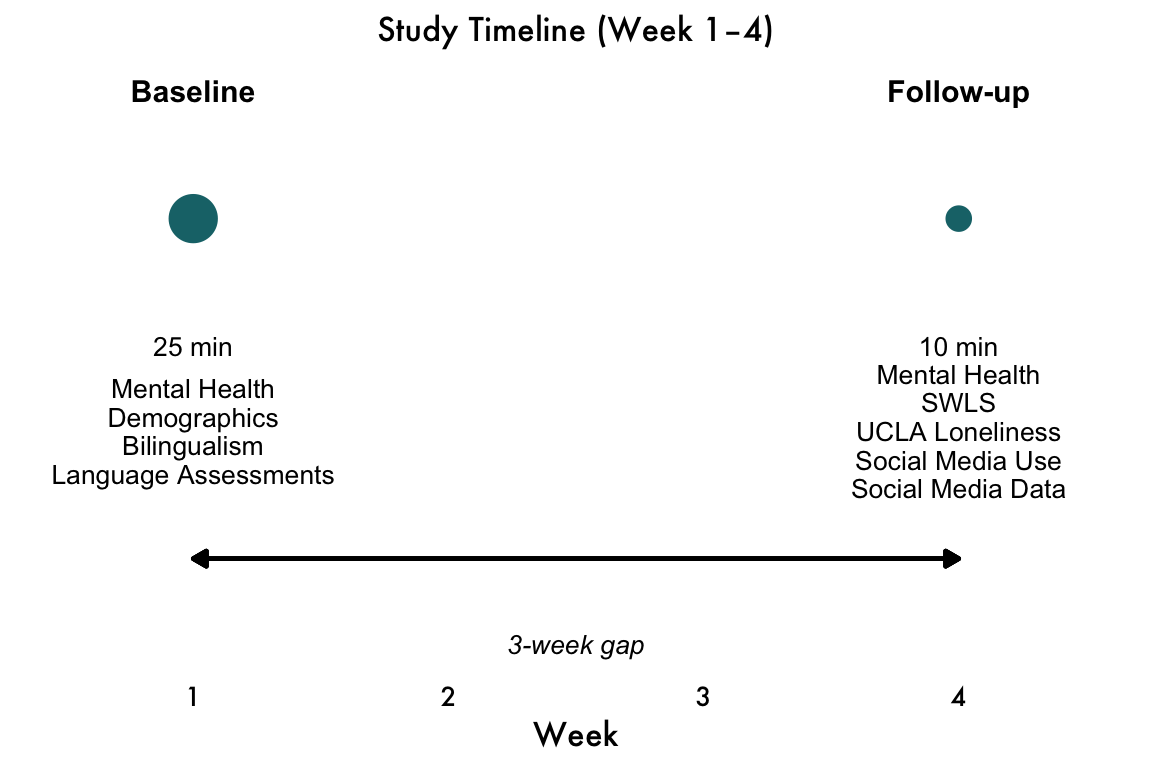
Measures
Depression-related Open-ended Questions
- At initial time point, participants will provide written responses to 9 open-ended questions about mood, motivation, sleep, energy, self-perception, and life satisfaction (≈150 words total; see below for full list of questions).
- Adapted from Hur et al. (2024)
- Conducted before mental health measures to avoid biasing responses.
Primary Mental Health Measures
- GAD-7 (anxiety; measured at both time points)
- PHQ-8 (depression; measured at both time points)
- If highly correlated, will collapse.
Standard Demographics
Assessed at initial timepoint
- Age: ___
- State of residence: ___
Other Measures…
- Initial Timepoint
- Bilingualism (using LEAP-Q)
- Both Timepoints
- Satisfaction with Life Short Scale
- UCLA Loneliness Scale
- Satisfaction with Life Short Scale
- Follow-up Only
- Social Media Use
- Social Media–derived Language-based Assessments
- Social Media Use
Aim 1 — Sensitivity Across Groups
Goal: Test prediction of current and future anxiety/depression across four racial/ethnic groups
Hypothesis: Reduced sensitivity for Black, Latino, and Asian participants vs. White participants.
Primary Analyses:
- Moderation:
lm(symptoms ~ race * ling_feat, data = data)
- Linguistic features include (see Eichstaedt et al., 2021, Kern et al., 2016 for more info):
- Sentiment, pronouns, emotion words (LIWC)
- LLM-based inferences (e.g., GPT-4, LLaMA)
- Contextual embeddings (e.g., BERT, RoBERTa)
- Sentiment, pronouns, emotion words (LIWC)
Aim 2 — Markers in Minority Groups
Goal: Exploratory/descriptive identification of linguistic markers of mental illness in minority groups.
- Sentiment, pronouns, emotion words (LIWC)
- LLM-derived inferences (e.g., embeddings, LLM-based ratings, etc.)
Analyses:
- Descriptive statistics of linguistic features by racial/ethnic group
- Identify features associated with higher/lower symptom levels for each group - Exploratory correlations and regressions for hypothesis generation
Questions we have for you
- We are worried about the racial groups being treated as monoliths and thus want to capture (i) finer-grained racial/ethnic/cultural identities and (ii) relevant cultural dimensions that might relate to our research questions. This project can inform how culture shapes the linguistic markers of psychopathology, a question we’d love your help to address! Any thoughts welcome, but in particular:
- Any advice for best ways to assess racial/ethnic/cultural identities at a fine grained level than standard approach?
- Any other demographic factors should we consider?
- We would like to consider SES/class in particular:
- Any advice on measures?
- Should we worry about statistical power / diversity of online sample? How to handle multi-racial identities in modeling?
- What theories should we read to inform overall research question? What scales should we include to capture relevant cultural dimensions?