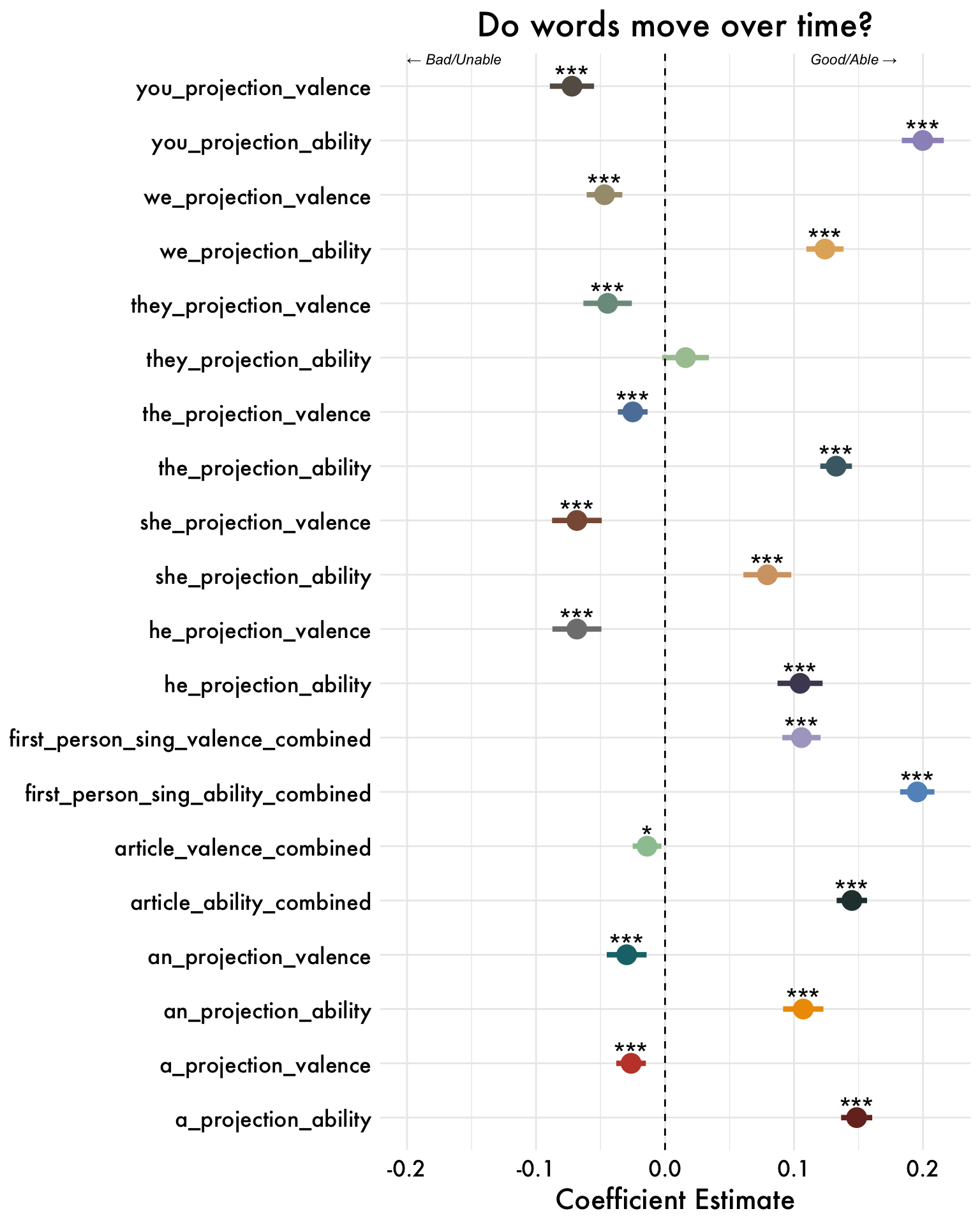
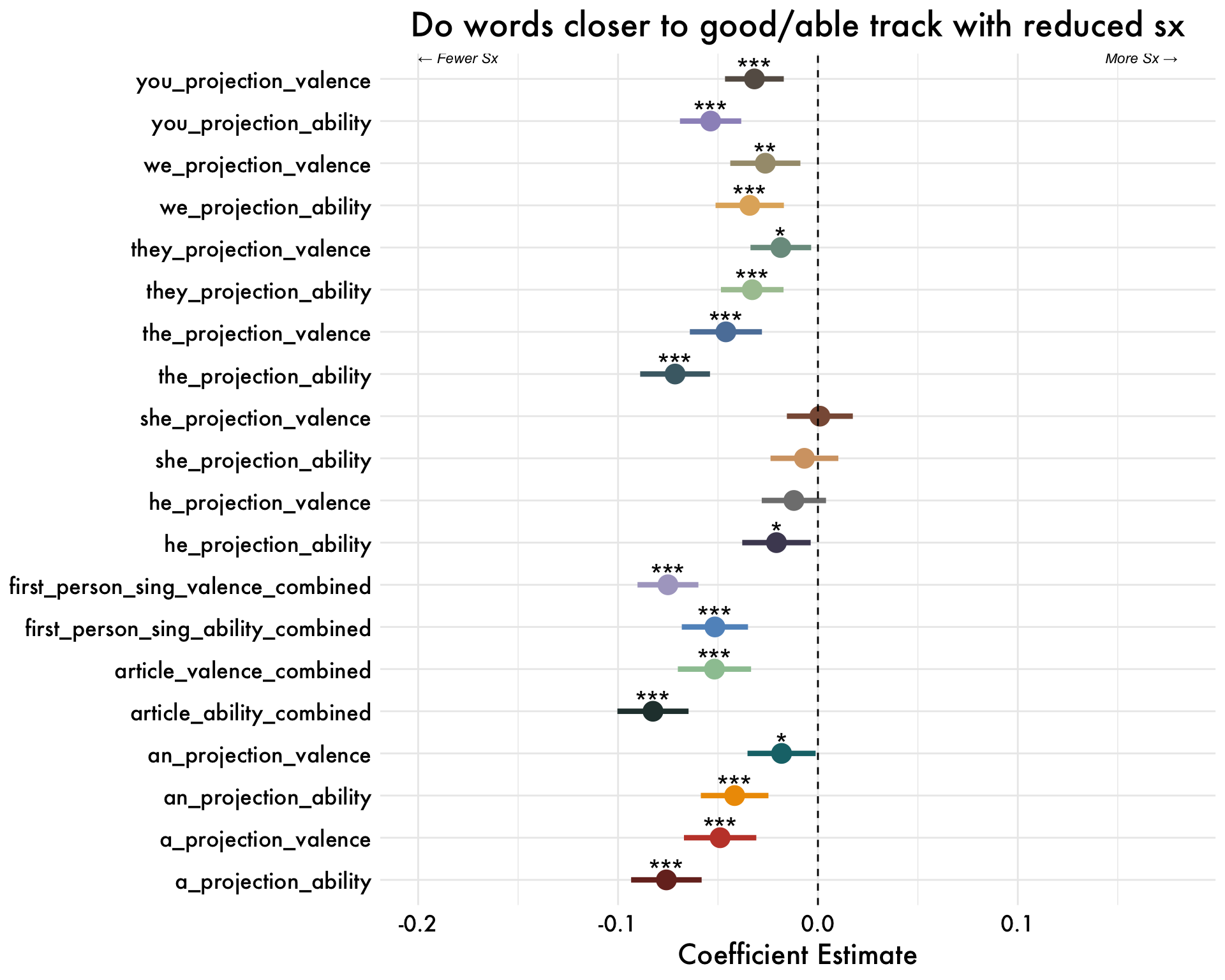
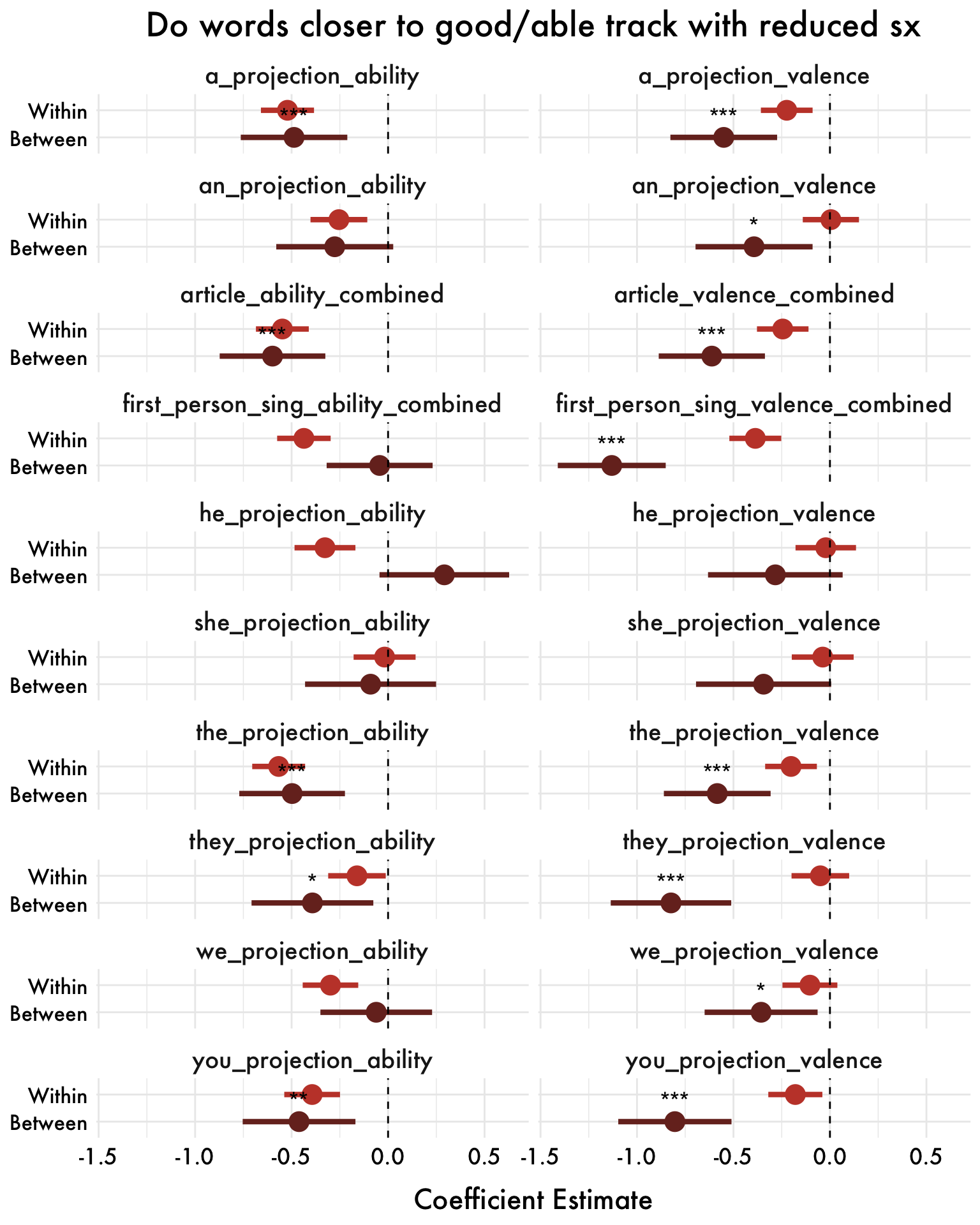
I-Projection Results
2026-01-28
first_person_sing_valence_combined individual variation
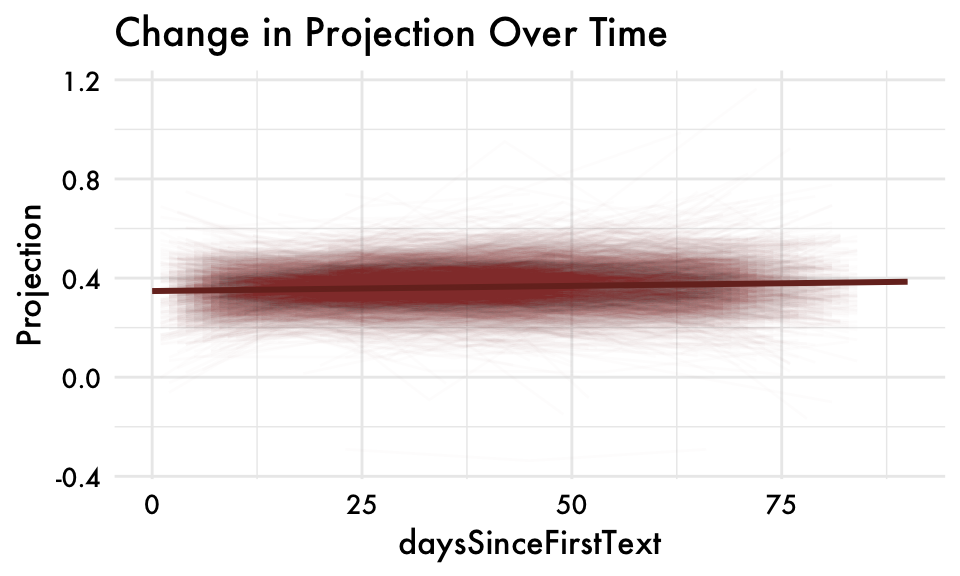
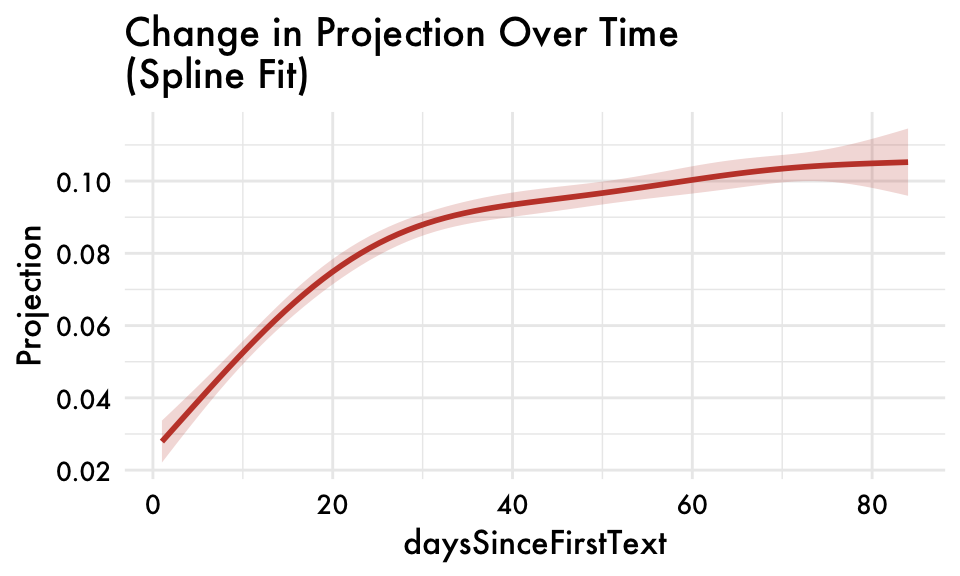
first_person_sing_valence_combined spline fit
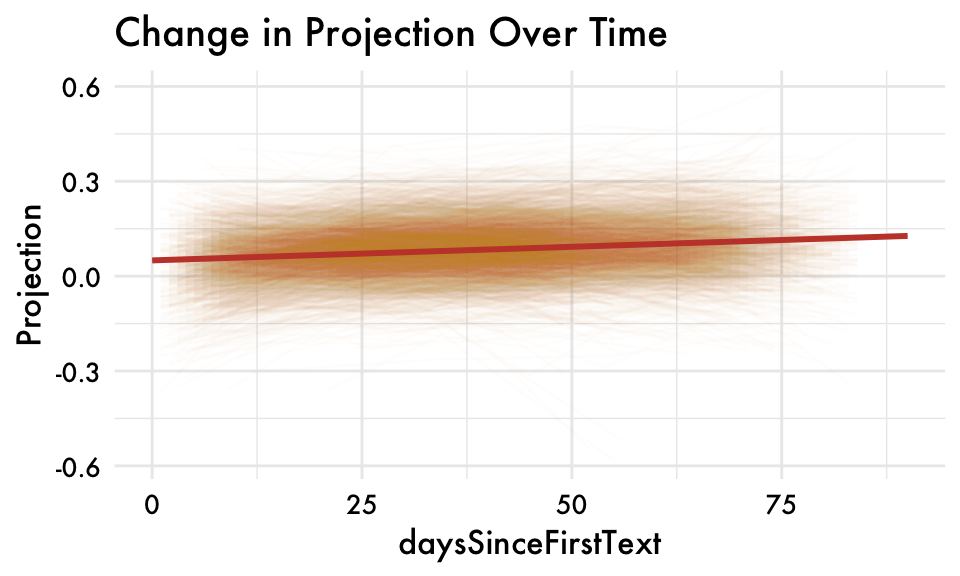
first_person_sing_ability_combined individual variation
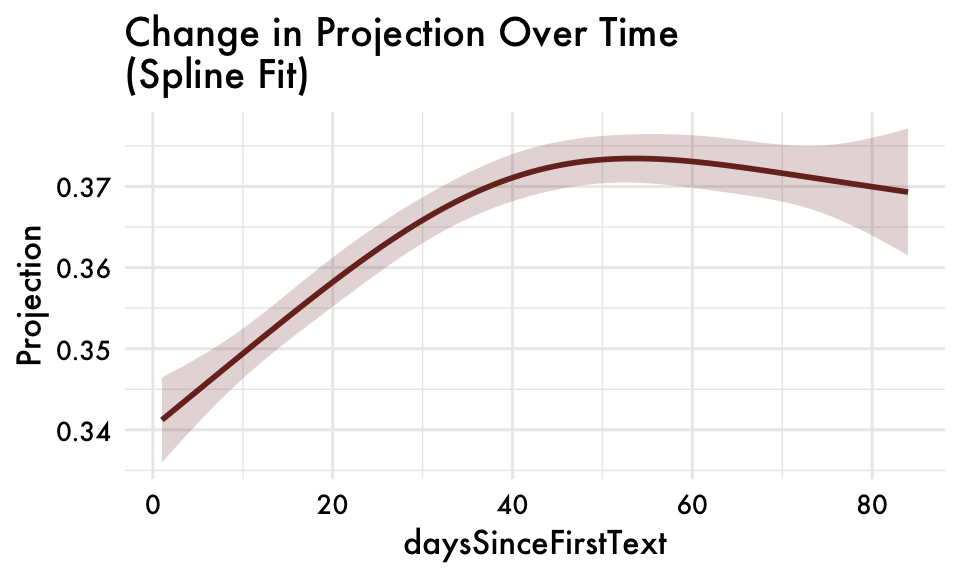
first_person_sing_ability_combined spline fit
Changes in Meaning over Time